
检索到了,为什么还是答错?——PruneRAG 瞄准 RAG“证据遗忘”难题
PruneRAG 论文——该成果已经被国际顶级学术会议 The Web Conference (WWW2026)正式录用

在大模型应用快速落地的今天,RAG(检索增强生成)几乎成为知识密集型AI系统的“标配”。
但一个很少被正面讨论的问题正在浮现:模型已经检索到了正确答案所需的关键证据,为什么还是会答错?这并不是个例,而是一类系统性问题。
近期,由哈尔滨工业大学(深圳)与立谱智造联合研究团队提出的 PruneRAG 框架,关注的是检索增强生成(RAG)系统里一个非常常见、但长期没有被充分刻画的问题:模型已经检索到了关键证据,却没有在后续推理中真正把这些证据用起来。
这种现象在多跳问答任务中尤其明显。随着推理步骤不断增加、上下文持续累积,前面检索到的重要信息很容易被后续内容冲淡,最终模型虽然“见过”关键证据,却依然给出了错误答案。
PruneRAG 关注的,正是这一类 evidence forgetting(证据遗忘) 问题。这项工作的核心目标,并不是单纯让模型“检索更多”,而是让它在拿到信息之后,能够更稳定地保留、筛选并利用这些信息。
从这个角度看,PruneRAG 更像是在优化 RAG 的推理控制机制,而不只是增加一个新的检索模块。
过去讨论 RAG,大家往往更关注检索能力,例如文档能不能召回、证据能不能找准、知识能不能补齐。但在复杂推理任务中,系统出错往往还有另一层原因,那就是证据利用失败。
也就是说,问题未必出在“没有找到信息”,而可能出在:
1)关键证据已经进入上下文,却没有真正参与后续推理;
2)早期检索到的正确信息被后续冗余内容覆盖;
3)模型沿着一条质量不高的路径继续展开,导致错误不断被放大。
这也是为什么,单纯增加检索次数并不一定会带来更好的最终效果。更多检索有时意味着更多证据,但也意味着更多噪声、更长延迟,以及更难控制的推理过程。PruneRAG 想解决的,正是这一层问题:当模型已经拿到证据之后,怎样才能更可靠地使用这些证据。
为了更准确地刻画这个现象,PruneRAG 引入了一个新的指标:Evidence Forgetting Rate(EFR)。
这个指标关注的是这样一种情况:标准答案所需的黄金证据已经被完整检索到,但模型最终仍然回答错误。
EFR 的意义在于,它把“检索是否成功”和“证据是否被有效利用”拆开来看。传统的 EM、F1 只能告诉我们最后答得对不对,但 EFR 更进一步追问:如果证据都已经给到了,为什么还是没答对?这个视角很重要。
因为它意味着,RAG 的优化不能只停留在“提高召回率”这一层,还要进一步关注模型如何在多步推理过程中维持证据的可用性,避免关键线索在中间步骤中被冲淡、遮蔽甚至遗失。
从整体上看,PruneRAG 建立在一个结构化的 Query Decomposition Tree 上。面对复杂问题时,系统不再沿着单条推理链一路往下走,而是把问题逐步拆成更小的子问题,再通过回溯把各个分支的信息重新聚合回来。
但仅仅“做成树”并不够。树结构如果缺乏控制,反而容易引入大量低价值节点和冗余搜索。因此,PruneRAG 的关键不只是 tree,而是在 tree 上增加了更细致的推理控制机制。
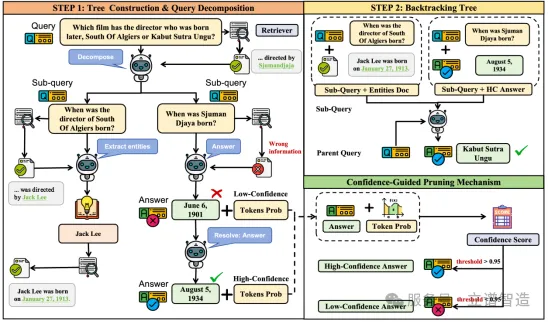
PruneRAG整体框架图
1. 自适应扩展:不是所有问题都值得一直拆下去
在很多多跳 RAG 方法里,问题分解往往会不断向下展开。但这种持续扩展并不总是有益,有时反而会让推理过程越来越冗长,也越来越不稳定。因此,PruneRAG 让每个节点都动态判断当前最合理的动作:
如果现有证据已经足够,且模型可以给出高质量答案,就直接在当前节点停止; 如果问题还可以继续拆解,就生成更基础的子查询,递归求解; 如果既不能直接回答,也不适合继续拆解,就转向实体级检索。
换句话说,PruneRAG 并不希望推理树无边界地生长,而是希望它在必要的时候展开,在合适的时候停止。
2. 置信度剪枝:不让低质量中间答案继续往后传
这是 PruneRAG 最核心的设计之一。在多步推理里,真正危险的往往不是最后一步,而是中间那个“看起来像对了、实际上并不稳”的答案。一旦系统过早接受了这样的中间结果,后面的整条路径都可能建立在错误前提之上。
因此,当模型在某个节点生成候选答案后,PruneRAG 不会直接接受,而是先根据答案序列的 token-level probability 计算一个整体置信度。
如果置信度足够高,就接受这个答案,并停止当前分支的进一步扩展; 如果置信度不足,就拒绝当前答案,继续拆解问题,或者转向更细粒度的检索。
这一步相当于给多步 RAG 加了一个“中间结果验收机制”。系统不再是“只要生成了答案就继续往下走”,而是要先判断:这个答案到底值不值得信。
3. 细粒度检索:问题拆不动的时候,不硬拆,而是换一种方式找证据
并不是所有 query 都适合持续分解。有些问题如果继续往下拆,反而会破坏原始语义结构,引入新的误差。
因此,PruneRAG 设计了一个兜底策略:当一个问题已经不适合继续拆解时,系统会自动提取其中的关键实体,例如人物、地点、事件或关系表达,把它们作为更精确的检索锚点执行 retrieval。
这意味着系统不会因为“拆不下去”就停住,也不会为了维持树结构而生硬地继续分解,而是切换到一种更适合当前状态的证据补充方式。很多复杂问题走到最后,真正缺的并不是“更多推理”,而是一次更准的检索。
4. 底向上的回溯:把分散在树上的证据重新聚起来
在整棵分解树构建完成之后,PruneRAG 会执行一个 bottom-up backtracing 过程:从叶子节点开始,逐层向上聚合中间答案与支持证据,最终在根节点形成最终输出。
这个过程不是简单的信息拼接,而是为了保证信息能够从局部节点稳定回流到全局问题,尽可能减少“前面找到了、后面又丢掉”的情况。可以把它理解成这样:前面的分解和检索是在“分散找线索”,后面的回溯聚合是在“重新组织线索”。
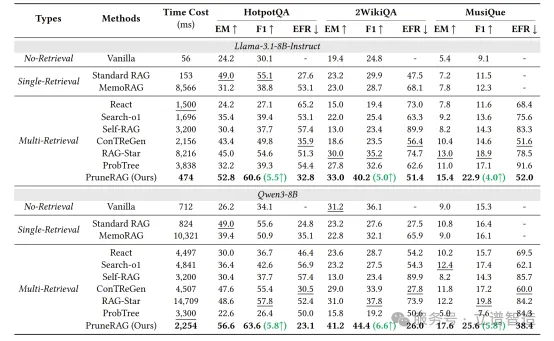
PruneRAG实验结果表
在 HotpotQA、2WikiQA 和 MusiQue 三个多跳问答数据集上,PruneRAG 在 Llama-3.1-8B-Instruct 和 Qwen3-8B 两个 backbone 下都取得了更强的综合表现。
相比最强 baseline,PruneRAG 平均 F1 提升 5.45%,平均 推理速度提升 4.9 倍,同时将平均 证据遗忘率(EFR)降低了 20.8%。
以 Qwen3-8B 为例,PruneRAG 在 HotpotQA / 2WikiQA / MusiQue 上分别达到 56.6 / 41.2 / 17.6 EM,对应的 F1 为 63.6 / 44.4 / 25.6,同时 EFR 降到 23.1 / 26.0 / 38.4。
这说明它的提升不只是体现在最终答案更准,也体现在已经检索到黄金证据时,更不容易把这些证据“忘掉”。
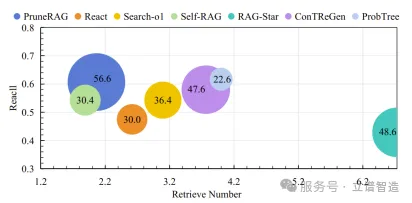
实验结果气泡图
气泡图实验结果更直观地说明了 PruneRAG 的优势并不是靠“多搜几次”换来的。图中横轴是检索次数,纵轴是黄金文档召回率,气泡大小代表最终 EM。
可以看到,PruneRAG 在 检索次数只有约 2 次 的情况下,就取得了接近 0.61 的 recall 和 56.6 的 EM,整体位置明显优于多数 baseline。相比之下,一些方法虽然检索次数更多,但并没有带来更高的最终准确率。
这两组结果放在一起,其实说明了一件很重要的事:RAG 的问题并不只是“能不能检索到”,更在于“检索到之后能不能真正用好”。
PruneRAG 的改进,不是简单增加搜索深度或检索轮数,而是通过更好的推理控制,让系统在更少或相近的检索开销下,获得更高质量的证据利用效果。
也正因为如此,它才能同时做到更准、更快,也更不容易遗忘关键证据。
PruneRAG 的意义,不只是一个算法优化。它实际上在回答一个更关键的问题:当大模型进入真实业务场景,我们到底该优化什么?
答案正在发生变化。过去,我们习惯把优化重点放在“让模型知道更多”——不断提升检索能力、增加上下文长度、依赖更大规模的模型来覆盖更多知识。
但在实际应用中,这一思路正在逐渐失效。行业开始意识到,真正关键的,不再是信息获取本身,而是信息如何被使用。
与其一味提高检索能力,不如更精细地控制推理过程;与其不断堆叠上下文,不如管理好信息在系统中的流动与筛选;与其盲目追求更大模型,不如让模型在关键时刻做出更稳定、更可靠的决策。
对于企业级 AI(尤其是制造业、工程场景)来说,这一点尤为关键:错误不是“答偏一点”,而是决策风险;问题不是“不会”,而是不稳定。
而 PruneRAG 提供的,是一种更接近工程系统的思路:让模型在不确定时收敛,在确定时停止。
这项工作由哈尔滨工业大学(深圳)与立谱智造联合完成,如果说学术界在解决“模型能力边界”,那立谱智造更关注的是:如何把这些能力,变成可以稳定运行的工业级系统;让模型在复杂环境中,做出更可信的判断。